-
1. 지표.zip (Classifier Model Evaluation Metrics)ML 2021. 3. 28. 15:28

ML좀 한다하면 알만한 지표들 정리 분류 모델을 학습시키고 생성하는 방법은 추후 다룰 예정이지만, 오늘은 우선 생성된 분류기의 성능을 판단하는 지표에 대해 알아보려 합니다. 판단 지표는 여러 가지가 있지만 대표적인 10가지에 대해 알아보고, 어떠한 상황에서 무엇이 적합한 지표인지 알아보겠습니다.
1. Confusion Matrix
2. Type 1 Error
3. Type 2 Error
4. Accuracy
5. Recall
6. Precision
7. Specificity
8. F Score
9. ROC curve - AUC score
10. PR Curve
1. Confusion Matrix (오차 행렬)
In the field of machine learning and specifically the problem of statistical classification, a confusion matrix
, also known as an error matrix, is a specific table layout that allows visualization of the performance
of an algorithm, typically a supervised learning one (in unsupervised learning it is usually called a matching matrix).
Source: https://en.wikipedia.org/wiki/Confusion_matrix오차 행렬이란 실제 분류 값과 예측 분류 값 사이의 분포 관계를 표로 나타낸 것입니다. 설명을 간단하게 하고자 분류 값이 yes/no 두 개의 label이라고 가정하겠습니다.

Source: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 오차 행렬 내부는 4개의 cell로 구성이 되어있는데 각각 TP, TN, FP, FN으로 지정이 됩니다.
1. TP (True Positives): 실제 값도 'YES'이고 예측 값도 'YES'인 경우.
2. TN (True Negatives): 실제 값도 'NO'이고 예측 값도 'NO'인 경우.
3. FP (False Positives): 실제 값은 'YES'이고 예측 값은 'NO'인 경우
4. FN (False Negatives): 실제 값은 'NO'이고 예측 값은 'YES'인 경우
이를 통해 데이터의 특성뿐만 아니라 분류기의 예측력도 판가름할 수 있게 됩니다.
2. Type 1 Error
실제 값 'NO'를 'YES'라고 예측하는 것을 Type 1 Error라고 하며 오차 행렬에서 FP로 나타납니다.
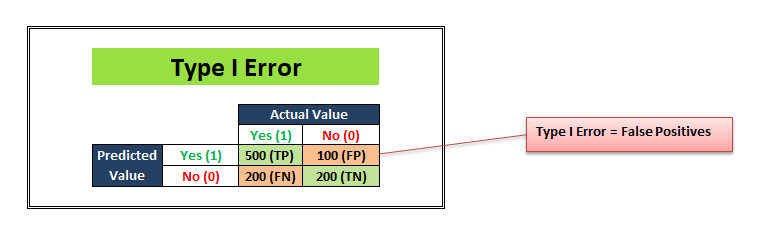
Source: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 Type 1 Error가 날 수록 분류기의 'NO'(거짓) 판별 능력이 떨어진다는 것을 의미하게 됩니다.
3. Type 2 Error
실제 값 'YES'를 'NO'라고 예측하는 것을 Type 2 Error라고 하며 오차 행렬에서 FN으로 나타납니다.

Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 Type 2 Error가 날 수록 분류기의 'YES'(참) 판별 능력이 떨어진다는 것을 의미하게 됩니다.
4. Accuracy
상기의 지표들은 데이터의 특성에 구애받지 않고 확인해 볼 수 있는 일반적인 지표들에 해당됩니다. 지금부터 살펴볼 지표들은 각 데이터의 특성을 이해하고 알맞게 활용할 필요성이 있는 지표들입니다.
Accuracy는 사용하는 데이터가 balanced 데이터 일 때 가장 사용하기 좋습니다. Balanced 데이터란 예측 및 구분해야 할 타겟 내부의 label들이 고르게 분포하는 것을 뜻합니다. 역으로 Imbalanced 데이터는 label의 분포가 특정 label로 과도하게 치우쳐져 있는 것을 뜻합니다.

Source: https://medium.com/analytics-vidhya/what-is-balance-and-imbalance-dataset-89e8d7f46bc5 
Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 Accuracy란 오차 행렬의 대각선 cell들의 합을 모든 cell의 값의 합으로 나눈 것과 같습니다. 대각선 cell들은 각각의 label을 얼마나 정확하게 예측하였는지 나타내어주는 값이라 할 수 있습니다.
Balanced 데이터의 경우 분류기의 accuracy가 70%라고 한다면 각각의 label들에 대한 개별의 예측력을 어느 정도 기대할 수 있습니다. 상기 이미지의 경우 'YES'와 'NO'의 비율은 7:3이며 'YES'를 700개 중 500개 예측해내었고 'NO'의 경우 300개 중 200개를 예측해내었습니다.
그렇다면 왜 Imbalanced 데이터에서는 사용하기 부적합하다고 이야기 한 걸 까요?

Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 상기 이미지는 'YES':'NO'의 비율이 9:1인 데이터입니다. Accuracy는 이전의 데이터보다 높은 72%로 나타나고 있지만 자세히 들여다보면 이야기가 다릅니다. 'YES' label 내부 예측력은 77% 정도이지만 'NO' label 내부의 예측력은 20% 정도로 급격하게 낮아진 것을 볼 수 있습니다. 이처럼 label의 imbalance가 커질수록 accuracy와 실제 예측력 간의 간극이 커지게 됩니다.
극단적 예시로 타겟 label 중 'yes':'no'의 비율이 10000:1 정도 일 경우, accuracy가 99.5%가 나오더라도 모델의 성능 부적합이 나올 수 있습니다.(모델 평가 기준이 정확도가 아닌 'no' 복원력이 우선시 될 경우)
이러한 문제가 발생하였을 때는 어떠한 방법으로 해결해야 할까요?
5. Recall/ Sensitivity/ TPR
실제 참 중 얼마나 알맞게 인식 되었는가?

Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 'YES' label 내부의 예측력(복원력)을 recall이라고 합니다.

Source: https://en.wikipedia.org/wiki/Sensitivity_and_specificity Recall은 주로 분류기 모델의 최우선 목적이 label 분류보다 각각의 label의 true-detection이 중요할 때 사용됩니다. 주로 Imbalance 데이터 중 분포가 적은 label을 얼마나 잘 복원하느냐를 보고 싶을 때 사용하는 경우가 많습니다. 예를 들어 환자들 중 누가 암에 걸릴 확률이 클지 분류하는 모델 생성 시 실제 암에 걸리는 환자들은 그 분포가 반대의 경우에 비하여 현저하게 낮기 때문에 분류보다 복원에 초점을 두는 것입니다.
6. Precision

Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 예측 결과 값 중 얼마나 실제로 맞는가(정밀도)?

Source: https://en.wikipedia.org/wiki/Sensitivity_and_specificity Precision은 최우선 목표가 모델 자체의 False-positive를 적게 하는 것이 가장 중요할 때 일반적으로 사용이 됩니다. 예를 들어 스팸 이메일 분류 모델 생성 시 예측 결과 상에서 스팸이지만 실제로는 스팸이 아닌 경우를 알려주는 기준이 precision입니다. Precision이 낮다면 모델 예측 결과 중 실제 값의 비율이 적다는 것이므로 모델 성능이 낮다고 이어질 수 있습니다.
7. Specificity

Scource: https://towardsdatascience.com/top-10-model-evaluation-metrics-for-classification-ml-models-a0a0f1d51b9 Specificity란 실제 거짓 중 예측 거짓의 비율을 나타냄.

Scource: https://en.wikipedia.org/wiki/Sensitivity_and_specificity Specificity를 사용하면 이전 예시였던 스팸 분류기에서 모델로 분류된 스팸 이메일 중 실제 스팸의 비율을 알아낼 수 있습니다. 분류기가 중요하게 생각하는 능력이 거짓 구별 능력 일 때 모델 성능 기준으로 판단하기 좋은 지표입니다.
8. F Score
Accuracy가 아닌 F1 score를 사용하는 경우는 데이터가 imbalance 할 때이다.

Source: https://en.wikipedia.org/wiki/F-score F1 score(F score)는 recall과 precision사이의 조화 평균입니다. 두 지표를 어느 정도 활용하여 전반적인 성능을 볼 수 있도록 고안된 지표입니다.
하지만 F1 score는 true negative를 활용하지 않기 때문에 Matthews correlation coefficient, Informedness, Cohen's kappa 등을 binary classification에서 활용하기도 합니다.

Source: https://en.wikipedia.org/wiki/F-score F1 score는 recall과 precision에 동일한 가중치를 부여한 조화 평균이기 때문에 이에 대해 문제를 제기한 사람들이 F beta Score를 만들었습니다. 여기서 beta는 recall을 precision보다 beta배만큼 중요하게 볼 것이다라는 상수입니다.
다음은 1 ~ 8번 항목까지의 요약본입니다. 자세한 내용을 링크를 보시면 체크하실 수 있습니다.

Source: https://en.wikipedia.org/wiki/F-score
9. ROC Curve & AUC Score

그렇다면 여기서 끝인 걸까? 우선 ROC Curve는 Receiver Operating Characteristics curve의 약자이며, AUC score는 Area under the Curve score의 약자이다.
Binary Classification의 결과는 0 또는 1이 나오게 된다, 하지만 여기에서 좀 더 수정을 할 수 있는 방법이 존재한다! 보통 예측 확률이 0.5 미만일 경우 0 인식되며, 반대의 경우 1로 인식을 하게 되며 이때 0.5를 threshold라고 하는데, 이 threshold를 움직이며 인식 기준을 변경할 수 있다.
ROC Curve는 x축에 1 - specificity를 놓고 y축에 sensitivity가 놓인다.
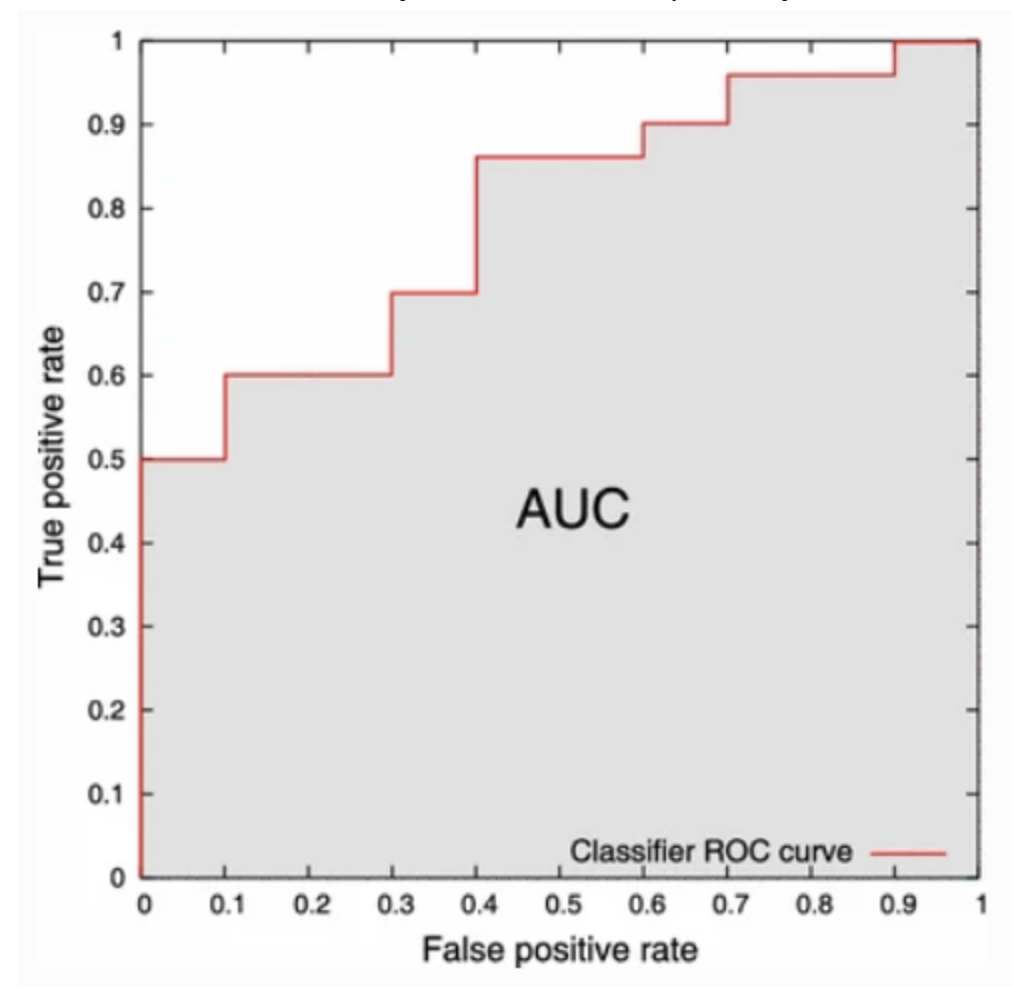
Source: https://bioinformaticsandme.tistory.com/328 ROC Curve은 x축이 0 ~ 1 사이에서 움직일 때 y값의 변화를 알 수 있으며 ROC Curve의 0 ~ 1까지의 적분 값이 AUC가 됩니다. Y = X인 linear regression보다 ROC Curve가 크다면 모델의 성능이 괜찮다고 볼 수 있으며 낮을 경우 모델 학습 및 구성을 다시 살펴볼 필요가 있습니다. AUC값이 클수록 모델의 성능이 좋다고 볼 수 있습니다.
10. PR Curve
데이터가 'NO' label에 분포가 치우쳐져 있을 때 ROC Curve는 'YES' 쪽 판별을 잘 분석해주기 때문에 실제 성능을 왜곡할 가능성이 있습니다. 그래서 PR Curve가 필요하게 됩니다.
PR Curve는 y 축에 Precision을 놓고 x 축에 Recall을 놓게 됩니다.
오늘은 기본적인 지표들에 대해서 알아보았습니다. 적시적소에 필요한 기준들을 활용하는 건 ML뿐만이 아니라 다른 분야에서도 중요한 것 같습니다. 다음에 만나길 바라며 오늘은 마치겠습니다.
참고자료
Top 10 model evaluation metrics for classification ML models
Explained unconventionally, this will serve as an exhaustive list for assessing classification Machine learning models.
towardsdatascience.com
F-score - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Statistical measure of a test's accuracy For the significance test, see F-test. In statistical analysis of binary classification, the F-score or F-measure is a measure of a test's accu
en.wikipedia.org
분류 모델 성능 평가 지표 - Confusion Matrix란? :: 정확도(Accuracy), 정밀도(Precision), 재현도(Recall), F1 Sc
분류 모델 성능 평가 지표 Linear 모델에 대해서는 R-Square, MSE 등 으로 모델의 성능을 평가한다. 그렇다면 분류 모델에 대해서는 모델의 성능을 어떻게 평가할 수 있을까? 여러가지 방법이 있지만,
leedakyeong.tistory.com
Model Evaluation I: Precision And Recall
To test the quality of any classification system like Support Vector Machines, there’s need to perform some evaluation metrics. Support…
towardsdatascience.com
Type I and type II errors - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives. Con
en.wikipedia.org
'ML' 카테고리의 다른 글
4. Boosting Methods (ft. XgBoost) (0) 2021.06.06 3. Random Forest (0) 2021.05.09 2. Tree - Based Model (Decision Tree🌳) (0) 2021.04.18